| How does Madrigal organize data? | Doc home | Madrigal home |
Understanding the organization of Madrigal data will help you understand the logic behind the way data is accessed through the web. In this section of the tutorial, a brief overview of the organization of Madrigal data is given, all the way from the highest level (a Madrigal site holding data from one group's instrument(s)) to the lowest level (a single measured value).
| A high level view of the Madrigal data model. | 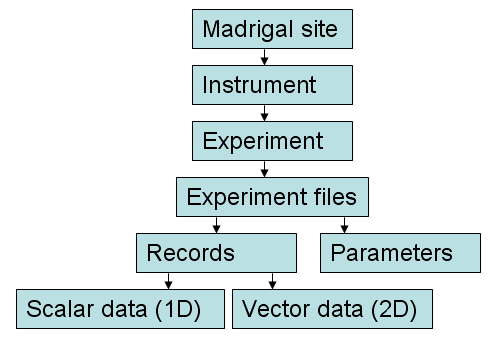 |
The highest level of Madrigal is a Madrigal site. A Madrigal site is one particular web site controlled by one particular group, that holds all their own data. While each Madrigal site stores their own data locally, they also share metadata with all the other sites. This makes it possible for you to search for data at all the Madrigal sites at once no matter which site you visit, and simply follow links to the Madrigal site that has the data you are interested in.
The next layer of the Madrigal data model is the instrument. All data in Madrigal is associated with one and only one instrument. Any given Madrigal site will hold data from one or more instruments. Since Madrigal focuses on ground-based instruments, most instruments have a particular location associated with them. However, some Madrigal data is based on measurements from multiple instruments, and so have no particular location. Some examples are "EISCAT Scientific Association IS Radars" which combine data from the multiple EISCAT radars, and "World-wide GPS Receiver Network", which consists of over a thousand individual GPS receivers distributed around the globe.
All the data from a given instrument is organized into experiments. An experiment consists of data from a single instrument covering a limited period of time, and, as a rule, is meant to address a particular scientific goal. Madrigal makes the assumption that instruments may be run in different modes, and so the data generated may vary from one experiment to another. By organizing one instrument's data into experiments, the purpose and limitations of each experiment can be made clearer. In Madrigal, you can navigate to a page that contains a particular experiment for a given instrument. This page may contain notes more fully describing the unique features of this experiment, or may contain plots of the data customized to the type of experiment. This level of organization is not presently maintained in the Cedar database.
For simpler instruments that run constantly in the same mode, it is also possible that all data is put in one experiment. For example, the "DST index" instrument consists of a single experiment that is repeatedly updated.
The data from a given experiment is stored in one or more experiment files. There are two reasons there may be more than one file for a given experiment. The first is that the experimental data may be analyzed in more than one way, leading to files with different sets of measured parameters. The second is that older, historical files can be kept on-line for reference purposes. By default, you will only access the most recent, default file through the web, unless you choose "Show History Files" when navigating Madrigal.
The format of these files is the CEDAR Madrigal Hdf5 format, but you can access the data in Hdf5, netCDF4, or ascii formats. Note that once to choose a particular file, you will be directed to the Madrigal site that has that file. Madrigal does not share experiment files between site; only higher level metadata about those files.
Any given file is made up a series of records holding measured parameters. Note that based on which parameters are in the file, Madrigal will automatically derive a large number of other parameters such as Kp and Magnetic field strength that aren't in the file itself. In the web browser, measured parameters are shown in bold, derived parameters in normal font.
The bottom level of the Madrigal data model is of course the data itself. With Madrigal 3.0 and beyond, the actual file format is Hdf5 that follows the rules defined in the CEDAR Madrigal Hdf5 format document. A Madrigal file is made up of a series of records, each with a start and stop time, representing the integration period of measurement (Madrigal tries to enforce the idea that all measurements take a finite time, but sometimes the start time = the stop time).
Each Cedar parameter can also have an associated error value. This error value can have the special values "missing", "assumed", or "known bad". If an error parameter is "assumed", the implication is that the measured value itself is assumed, and does not represent a measured value. If the error value is "known bad", the measured data is known to have a problem.
| How does Madrigal organize data? | Doc home | Madrigal home |